Model Manager
Finding a way to get models into production seems like a universal problem these days. 1.75 billion results as of last count, with countless companies devoted to solving this in one way or another.
The Problem⌗
At Windfall, we used a variety of models built by data scientists to drive our products. The problem was that different people had slightly different ways of building them, and so there was no standard way of running them.
We relied heavily on whoever built the model in order to run it whenever we needed predictions. We also were exploring tying in model predictions directly into our front-end systems. There were a few existing solutions at the time, but after trialing them out, none really seemed easy enough to use or integrate with our systems, so I decided to build a relatively simple solution in-house.
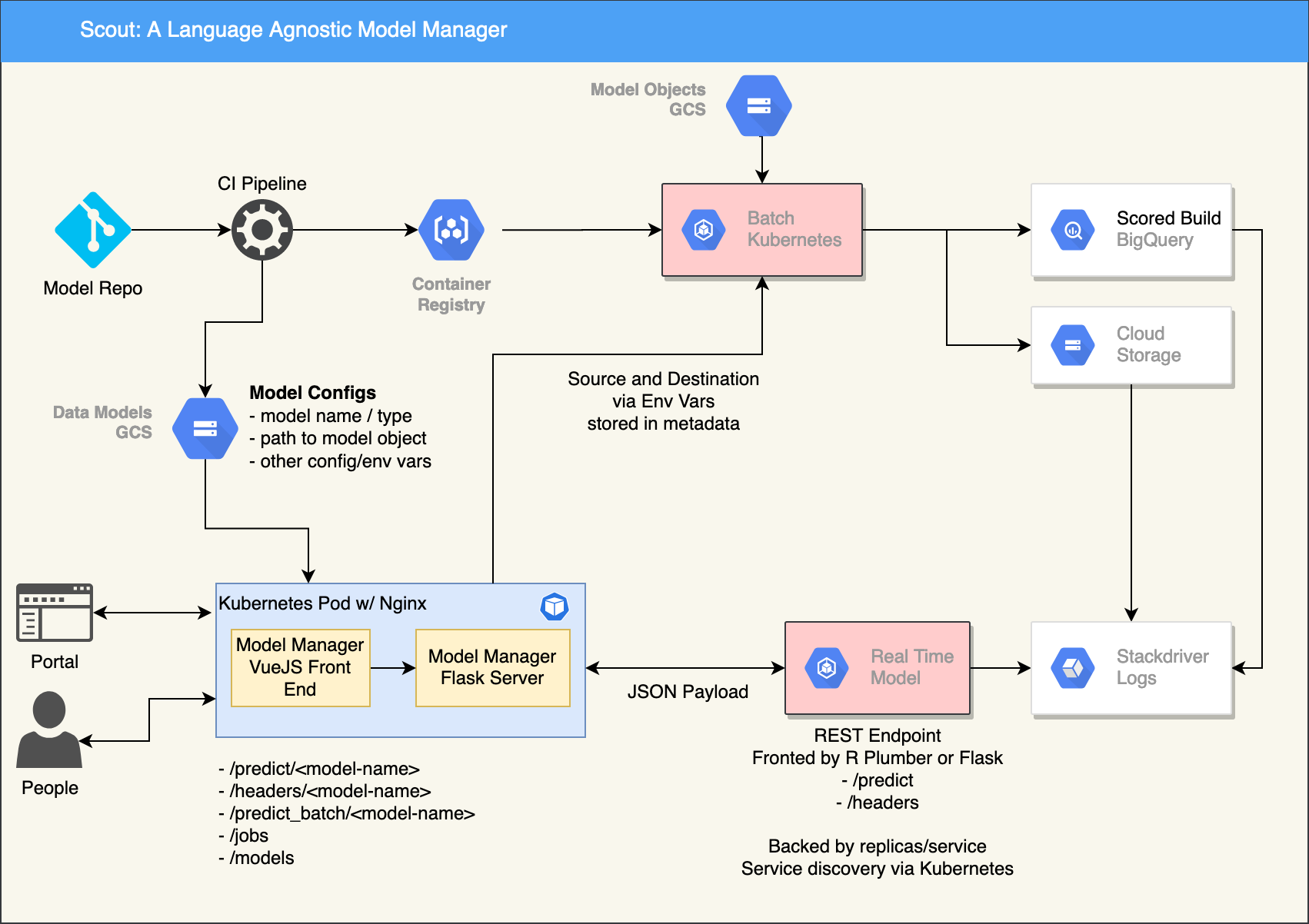
Requirements⌗
One of our first debates was what language should the models be written in. Some engineers suggested that we ask the data scientists to just write everything in Python, making it easier to integrate for engineering. I felt that was a non-starter. Asking data scientists to rewrite code didn’t sit right.
Another requirement was to have something that can be used as easily by a human as it can by a backend.
Finally, I wanted to hide the implementation details as much as possible, while making the system extensible and not tightly-coupled with any particular platform.
The Solution⌗
To solve the first problem, I opted for containerized approach. Data Scientists should be free to write using whatever language they wish, so long as we could agree on an interface. We had a couple different types of models, both real-time and batch, and so the interface for each of these was rather straightforward.
On the batch side, the container should expect a dataset as an environment variable, and it should return a location where the results will be saved as a JSON response.
For real time model, I opted for a simple REST interface with a few endpoints. The client is responsible for providing the data, and the container is responsible for returning a simple score, one for each row in the data provided.
Having built out the interface, the next question is where to run these containers. Leveraging Kubernetes was an obvious choice, as we already had the power of Google’s managed kubernetes environment at our disposal. Batch jobs could be run on large instances that auto-scaled down to zero to save on infrastructure costs, while real-time jobs could be horizontally-scaled as needed to serve the required thoroughput, while maintaining sufficient reliability.
The harder part is teaching a data scientist how to deploy to kubernetes. I opted to avoid this altogether, and decided to use our CI pipeline and some helpful bash scripts in order to automate the process. Whenever a commit was made to a models repo, some basic checks would run, the Docker image would build, and once a PR was accepted, the container would be pushed to our private container repo and made available for Kubernetes to run.
The last missing piece was orchestrating these Kubernetes runs on-demand. Here, I built a custom service called Model Manager. It was a two-part solution, with Flask as the backend and VueJS on the front-end. The backend was a simple orchestrator that hid the implementation details from the caller. It would get a list of available models through a shared filestore, make them available for any caller through a simple API, and then fire off requests to Kubernetes to start jobs for batch jobs, or route the request appropriately for real-time jobs.
Once the backend was built, the front-end was fairly straightforward, with just a few views that called endpoints in order to get a list of models, their status, and also the ability to trigger a model with the click of a button.